pccx: Parallel Compute Core eXecutor¶
NPU Architecture Overview¶
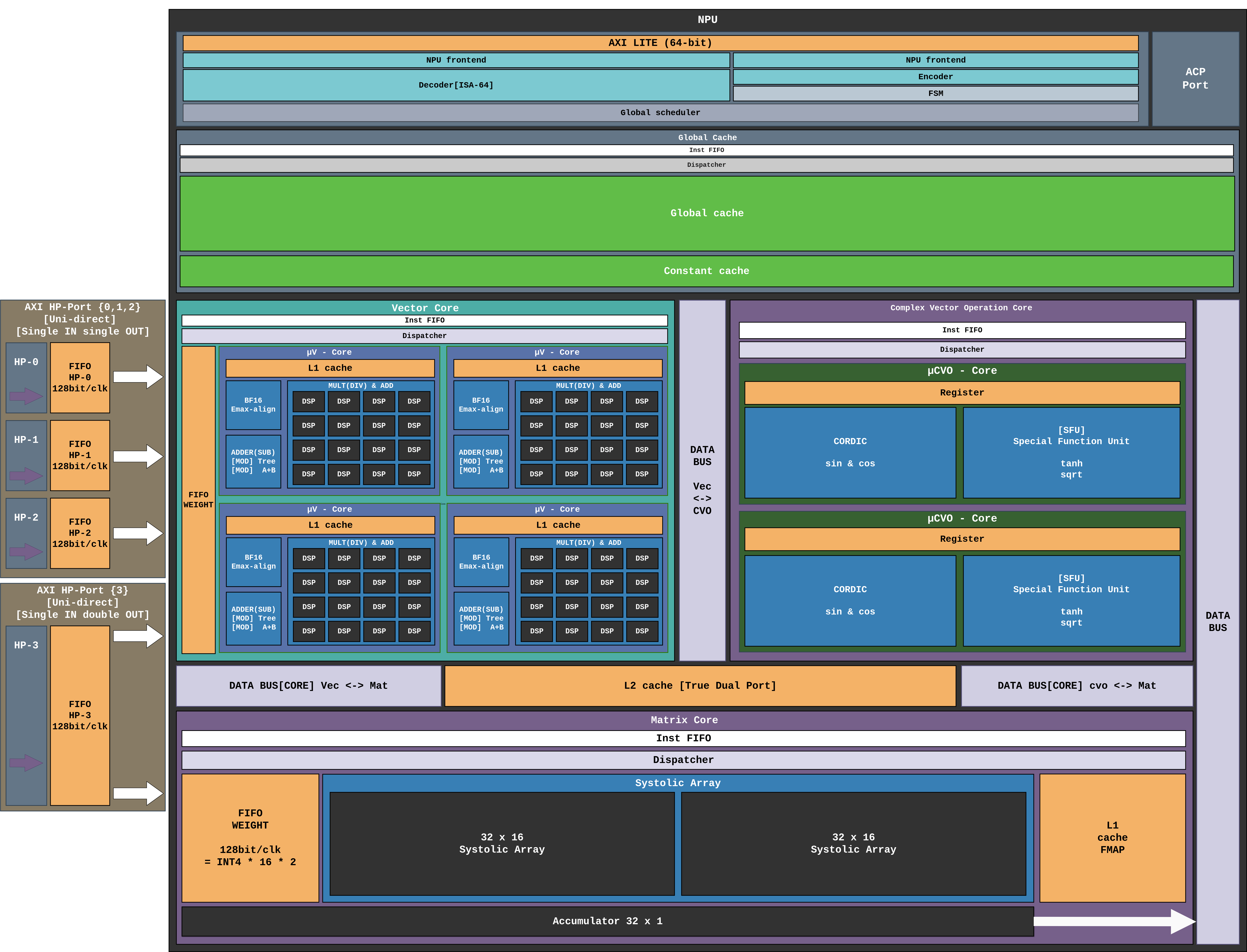
Figure 14 NPU Architecture¶
AXI-Lite (HPM) ──► NPU Controller ──► Global Scheduler
│
┌───────────────┬───────────────┼───────────────┐
▼ ▼ ▼ ▼
Vector Core Matrix Core CVO Core mem_dispatcher
(GEMV_top) (GEMM_systolic_top) (CVO_top) │
HP2/3 weights HP0/1 weights stream via L2 URAM cache
CVO bridge (114,688 × 128-bit)
└───────────────┴────────────── ─ ─ ─ ─ ─ ─ ─ ┘
preprocess_fmap (ACP fmap in)
The NPU is organized into three primary compute tiers connected via a shared L2 True Dual-Port cache and internal data buses:
Vector Core: Four μV-Cores for parallel GEMV operations, each with a dedicated L1 cache and BF16 Emax-align unit. Fed by AXI HP-Ports 2 and 3 (32 INT4 weights/clk each).
Complex Vector Operation (CVO) Core: Handles non-linear activation functions (GELU, sqrt, exp, sin/cos via CORDIC and SFU). Connected to the L2 cache via a dedicated CVO stream bridge (
mem_CVO_stream_bridge).Matrix Core: A 32×32 Systolic Array for GEMM operations. Weights supplied via AXI HP-Port 0/1 at 128-bit/clk. FMap is cached in a dedicated L1 FMAP cache.