GEMM 코어 (시스톨릭 어레이)¶
GEMM 코어는 Transformer 의 프리필(Prefill) 단계에서 지배적인 대규모 행렬 곱셈을 담당합니다. pccx v002 는 32 × 32 2 차원 시스톨릭 어레이 1 개 를 사용하며, 누적 cascade 가 16 행에서 끊겨 같은 물리 격자를 공유하는 32 × 16 서브체인 2 개로 동작하여 이론 피크 819 GMAC/s @ 400 MHz 를 제공합니다.
참고
GEMM 은 주로 프리필(배치·시퀀스 길이 큰 초기 프롬프트 처리) 과
Attention 의 Q·Kᵀ, score·V 에서 사용됩니다. 디코딩의 지배 연산인
GEMV 는 GEMV 코어 를 참조하세요.
1. 연산 대상¶
GEMM 은 다음과 같이 Weight (N × N) 와 Activation (N × N) 두 행렬의 곱을 계산합니다.
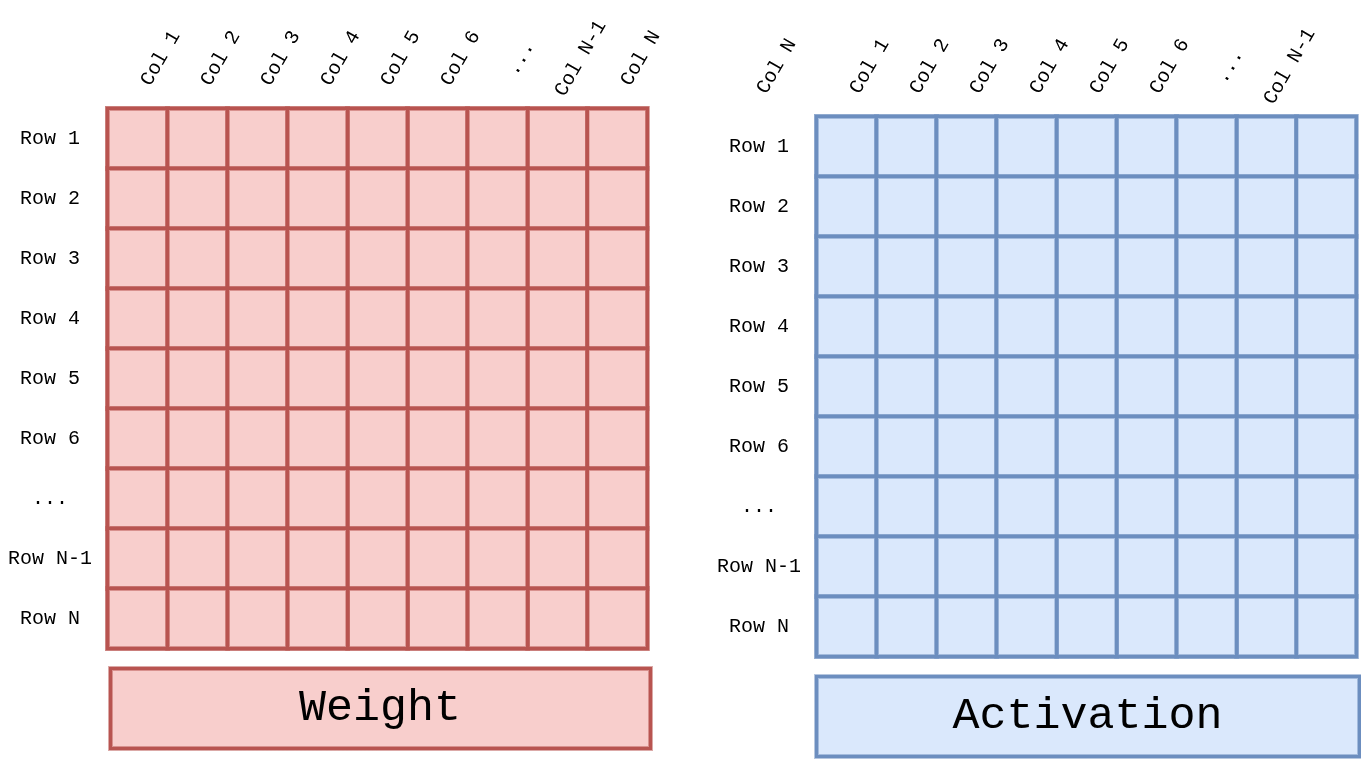
그림 3 Figure GEMM-Operands. GEMM 은 Weight 와 Activation 두 개의 2 차원 텐서를 입력받아 부분합(accumulation) 결과를 출력합니다. 양쪽 모두 Row × Col 로 정의되며, 타일링(tiling) 은 소프트웨어 계층에서 결정됩니다.¶
2. 어레이 구성¶
파라미터 |
값 |
|---|---|
물리 격자 |
32 (M) × 32 (K) → 1,024 PE |
Cascade 분할 |
16 행 에서 끊어짐 → 32 × 16 서브체인 2 개
( |
PE 당 DSP |
1 (DSP48E2) |
PE 당 MAC / clk |
2 (듀얼 채널 비트 패킹, DSP48E2 W4A8 비트 패킹과 부호 복원 참조) |
총 MAC / clk |
1,024 PE × 2 MAC = 2,048 |
피크 처리량 |
2,048 × 400 MHz = 819 GMAC/s |
3. 어레이 구조와 데이터플로우¶
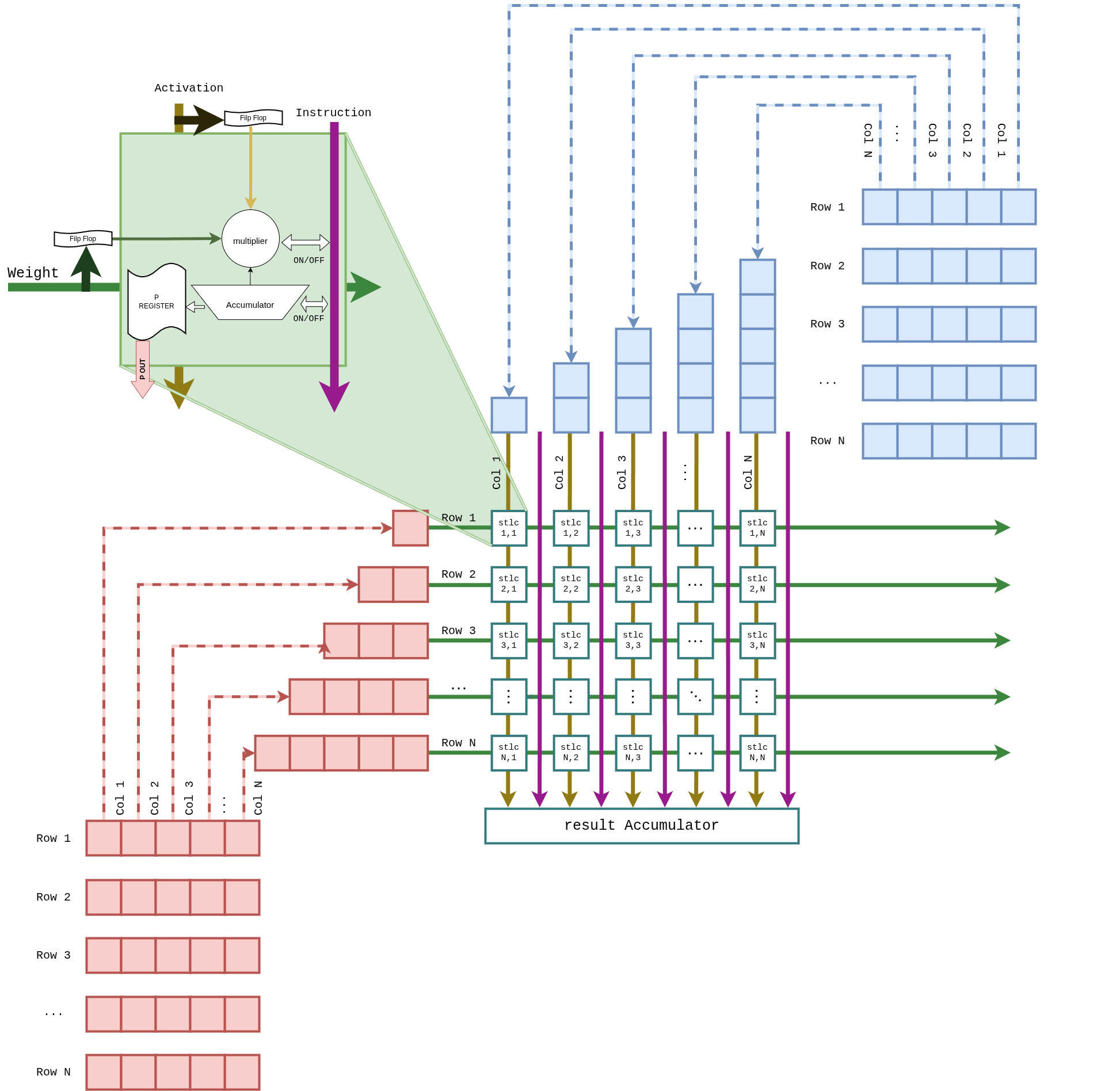
그림 4 Figure GEMM-Array. 시스톨릭 어레이는 좌측(가중치)·상단(액티베이션) 에서 PE 격자로 데이터를 주입하고, 하단의 Result Accumulator 에 부분합을 수집하는 Weight Stationary 구조입니다. 좌측 상단의 확대 박스(녹색) 는 한 PE 의 내부 구성을 나타냅니다.¶
3.1 Weight Stationary 재사용¶
GEMM 단계에서는 가중치가 여러 타일에 걸쳐 반복 사용되므로, 매 타일마다 HP 포트에서 가중치를 다시 읽지 않고 PE 내부 Flip-Flop 에 프리로드 합니다.
Weight Buffer 가 HP 포트에서 타일 크기 만큼의 INT4 가중치를 수신.
Weight Dispatcher 가 지그재그 staggered 분배로 각 PE 의 Port A 에 적재.
DSP48E2 의 27-bit Port A 에 {W₁ | 19-bit guard | W₂} 패턴으로 듀얼 채널 패킹 완료 (DSP48E2 W4A8 비트 패킹과 부호 복원 절 2).
이후 Activation 타일이 모두 스트리밍될 때까지 동일 가중치를 재사용.
3.2 Activation 스트리밍¶
L2 Cache 의 해당 타일 INT8 액티베이션이 시스톨릭 어레이 상단으로 주입.
각 열마다 fmap staggered delay 로 파이프라인 타이밍을 맞춤.
액티베이션은 어레이를 종단(수직) 으로 전파하며, 결과의 행 축은 어레이의 column 방향에 매핑됩니다.
flowchart LR
subgraph Host[Host DDR4]
W[Weights INT4]
end
WB[Weight Buffer<br/>URAM FIFO] -->|staggered| PE[(PE Grid<br/>32×32 · cascade break @ row 16)]
L2[L2 Cache<br/>URAM] -->|activations INT8| PE
PE -->|partial sums| RA[Result Accumulator]
RA -->|scale / requant| L2
W --> WB
3.3 누적 (Accumulation)¶
DSP48E2 의 48-bit P 레지스터에 K-depth 만큼 누적.
듀얼 채널 비트 패킹으로 인해 안전 누적 상한
N_max = 2²² / 2¹⁰ = 4,096.K > 4,096 인 경우 소프트웨어 계층에서 K-split 타일링으로 분할 수행.
3.4 결과 추출 & 부호 복원¶
누적이 끝나면 단 1 사이클의 후처리로 상·하위 채널을 분리하고, 하위 음수에 의한 borrow 를 복원합니다. 수학적 근거와 Verilog 구현은 DSP48E2 W4A8 비트 패킹과 부호 복원 에서 다룹니다.
4. PE 마이크로아키텍처¶
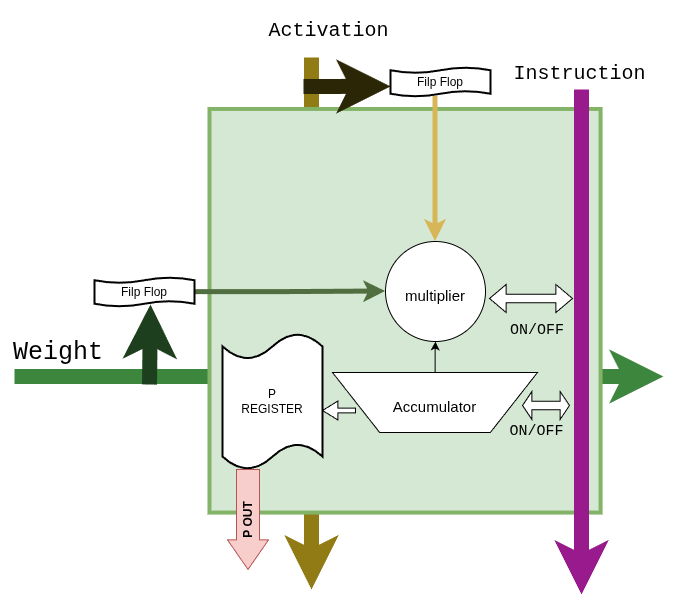
그림 5 Figure GEMM-PE. 단일 PE 는 Weight / Activation 입력 Flip-Flop,
DSP48E2 multiplier, P REGISTER, Accumulator 와 on/off 제어 신호로
구성됩니다. Instruction 포트는 명령어에서 추출한 μop (enable·flush·
accumulate-done) 를 전달하고, P_OUT 은 누적 완료 시 Result
Accumulator 로 출력되는 경로입니다.¶
파이프라인 스테이지는 DSP48E2 의 내장 레지스터를 모두 활성화하여 400 MHz 타이밍 클로저를 확보합니다.
단계 |
로직 |
설명 |
|---|---|---|
S0 |
Weight Register |
두 4-bit 가중치를 27-bit 패킹 형태로 래치. 재사용 기간 내 불변. |
S1 |
Activation Register |
상단 이웃 PE 로부터 INT8 액티베이션 수신. |
S2 |
DSP48E2 M-stage |
Port A × Port B (27 × 18-bit) 곱셈. |
S3 |
DSP48E2 P-stage (ACC) |
48-bit P 레지스터 누적. ON/OFF 제어로 flush/hold. |
S4 |
Propagate |
액티베이션을 다음 PE 로 전파. |
5. 포스트프로세싱¶
어레이 하단 Result Accumulator 이후에는 다음 단계가 순차 연결됩니다.
단계 |
기능 |
|---|---|
Result Accumulator |
어레이 경계에서 PE 결과 수집 및 상·하 채널 분리 부호 복원. |
Post-Process |
|
L2 Writeback |
ISA 의 |
관련 ISA 플래그는 명령어 상세 인코딩 의 GEMM 섹션 참조.
6. 확장성¶
어레이 크기는 SystemVerilog generate 파라미터로 노출됩니다.
파라미터 |
KV260 기본값 |
의미 |
|---|---|---|
|
32 |
가중치 / M 방향 PE 개수 ( |
|
32 |
액티베이션 / K 방향 PE 개수. 안전 누적 한계와 별개의 물리 크기. |
|
16 |
|
|
1 |
최상위 |
KV260 기준 32 × 32 격자는 DSP48E2 슬라이스 1,024 개 를 사용하여 디바이스 전체 1,248 개 예산의 약 82 % 를 점유합니다.