pccx: Parallel Compute Core eXecutor¶
NPU 아키텍처 개요¶
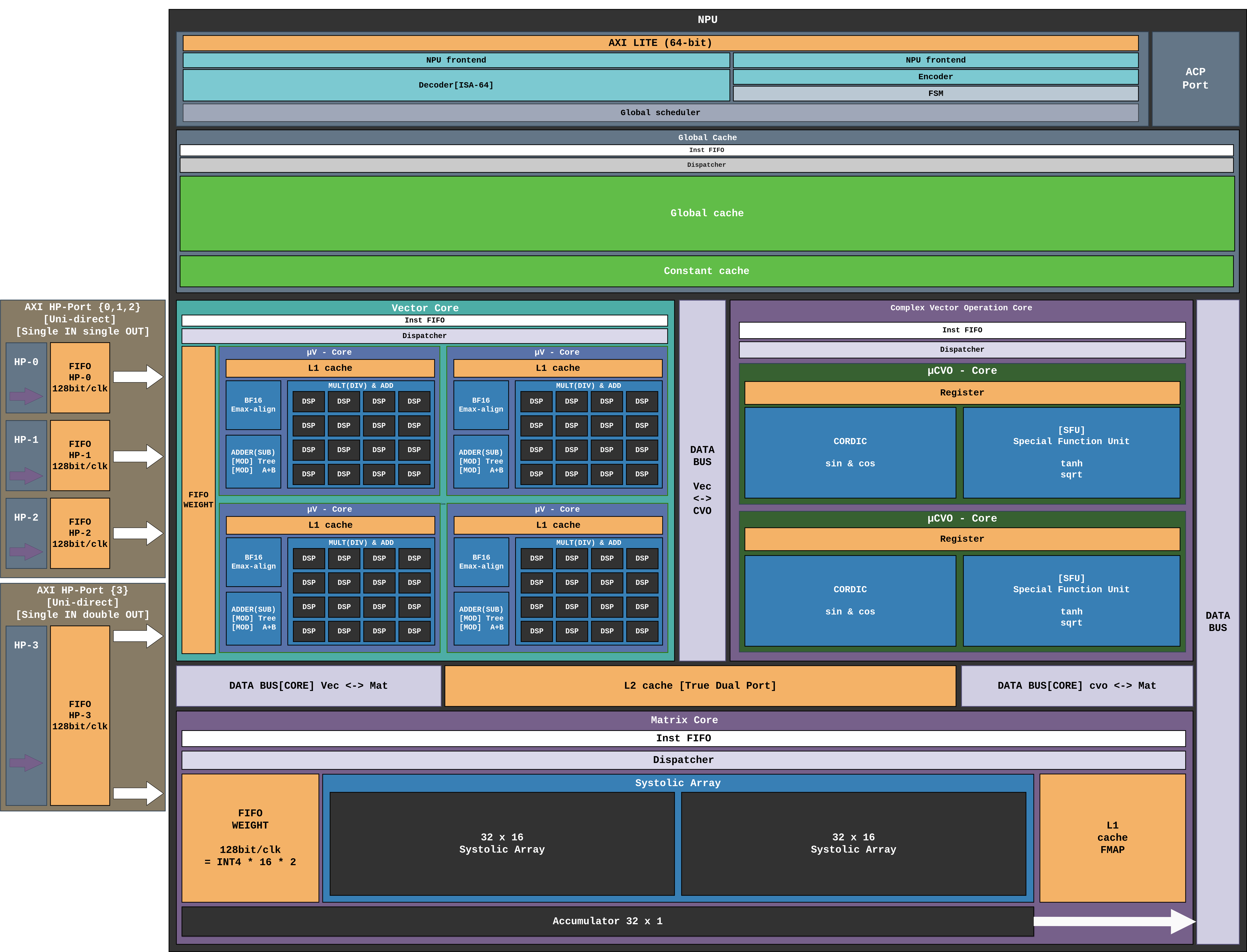
그림 14 NPU 아키텍처¶
AXI-Lite (HPM) ──► NPU Controller ──► Global Scheduler
│
┌───────────────┬───────────────┼───────────────┐
▼ ▼ ▼ ▼
Vector Core Matrix Core CVO Core mem_dispatcher
(GEMV_top) (GEMM_systolic_top) (CVO_top) │
HP2/3 weights HP0/1 weights stream via L2 URAM cache
CVO bridge (114,688 × 128-bit)
└───────────────┴────────────── ─ ─ ─ ─ ─ ─ ─ ┘
preprocess_fmap (ACP fmap in)
NPU는 공유 L2 True Dual-Port 캐시와 내부 데이터 버스로 연결된 세 개의 주요 컴퓨트 계층으로 구성됩니다.
Vector Core: 병렬 GEMV 연산을 위한 4개의 μV-Core. 각 코어는 전용 L1 캐시와 BF16 Emax-align 유닛을 가지며, AXI HP-Port 2/3 에서 클럭당 32 INT4 가중치를 공급받습니다.
Complex Vector Operation (CVO) Core: 비선형 활성화 함수 (GELU, sqrt, exp, CORDIC/SFU 기반 sin/cos) 를 담당. 전용 CVO 스트림 브리지(
mem_CVO_stream_bridge) 를 통해 L2 캐시에 연결됩니다.Matrix Core: GEMM 연산을 위한 32×32 시스톨릭 어레이. 가중치는 AXI HP-Port 0/1 로 128 bit/clk 공급되고, 피처맵은 전용 L1 FMAP 캐시에 상주합니다.